If You Think Distributed Systems Are Deterministic, Read This
Why partial failure, clock drift, and zombie nodes make reliability harder than you think

Everything works perfectly on your laptop.
Distributed systems exist to prove that reality is hostile.
On a single machine, failure is clean. A process crashes. A kernel panics. An exception throws. Something stops loudly and you fix it.
Then you deploy to the cloud.
Now multiple machines communicate over an unreliable network. Some fail. Some pause. Some lie. And none of them announce it clearly.
At 3:00 AM a service fails only 10 percent of the time. Data overwrites itself without errors. A node disappears, triggers failover chaos, then reappears five minutes later and corrupts your database. You spend hours debugging a timeout wondering whether the server crashed or whether someone cut a fiber cable hundreds of miles away.
Your code might not be broken.
Your mental model is.
Moving from single-machine programming to distributed systems requires a psychological reset. On one machine, failure is binary. In distributed systems, the defining reality is partial failure. Some components break while others continue operating as if nothing happened.
If you want reliability at scale, pessimism is not optional. Assume that anything capable of failing eventually will.
Here is why distributed systems behave the way they do and what you must understand to survive them.
1. The Illusion of “Now”
Treating a server clock as precisetime is a fatal mistake.
A timestamp is not truth. It is a guess.
Every machine runs two fundamentally different clocks.
Time of Day (Wall Clock)
Represents real world time
Synchronized via NTP
Can jump forward or backward
Unsafe for measuring elapsed duration
Monotonic Clock
Measures time since boot
Only moves forward
Safe for timeouts
Cannot be compared across machines
This distinction matters.
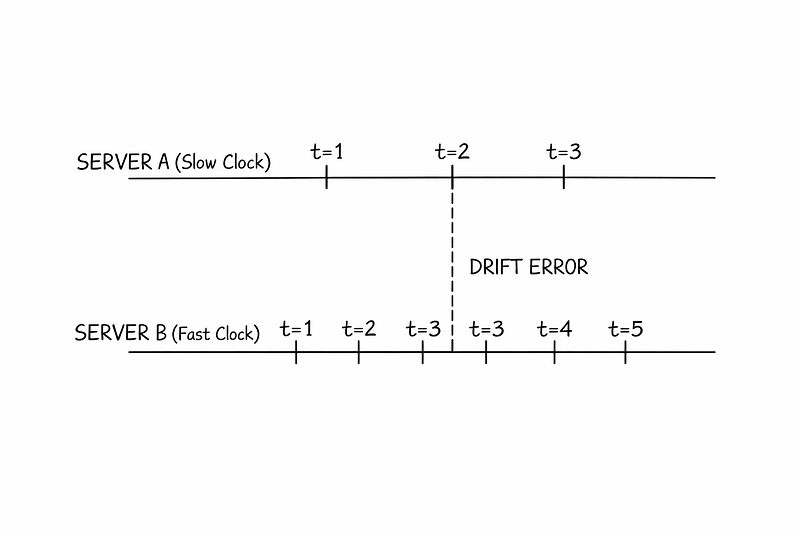
Many databases use Last Write Wins conflict resolution. They compare timestamps to decide which write is newer. But clocks drift. If Node A’s clock lags behind Node B’s, Node A’s writes may never win conflicts.
The result is silent data loss caused purely by clock skew.
Google’s Spanner database confronted this directly. Its TrueTime API returns a time interval rather than a precise timestamp and forces the system to wait out uncertainty before committing transactions.
Spanner encodes time uncertainty into the system itself.
Most systems do not.
2. The Ghost Node Problem
A node can fall asleep without knowing it.
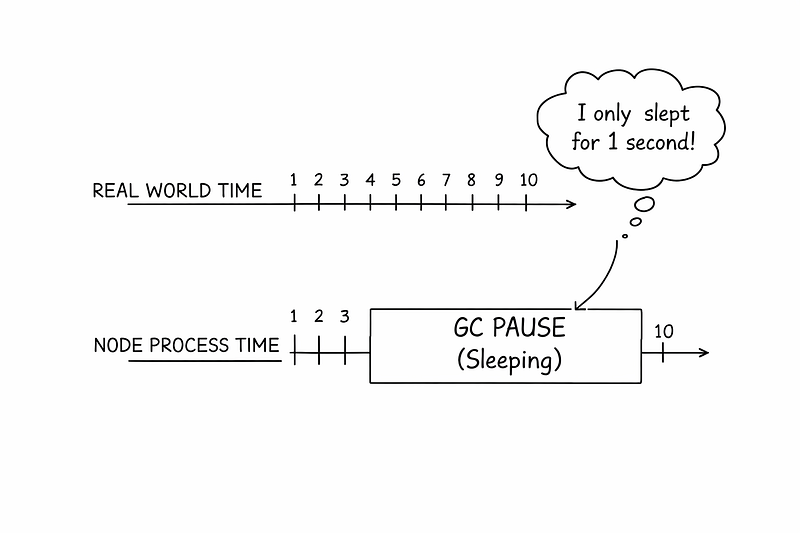
Imagine a leader node with 15 seconds remaining on its lease. Just before committing a write, the runtime triggers a stop-the-world garbage collection pause. The process freezes. Twenty seconds pass in real time. The lease expires. Another node becomes leader.
When the paused node resumes, it continues executing as if nothing happened.
It is now a zombie leader.
This happens for ordinary reasons:
Garbage collection pauses
Hypervisor pauses during VM migration
Operating system memory pressure
CPU starvation
Accidental process suspension
The node never knew it stopped. But the system moved on without it.
Without safeguards, that zombie can corrupt shared state.
3. The Unreliable Narrator
In asynchronous networks, you cannot distinguish between a dead node and a slow one.
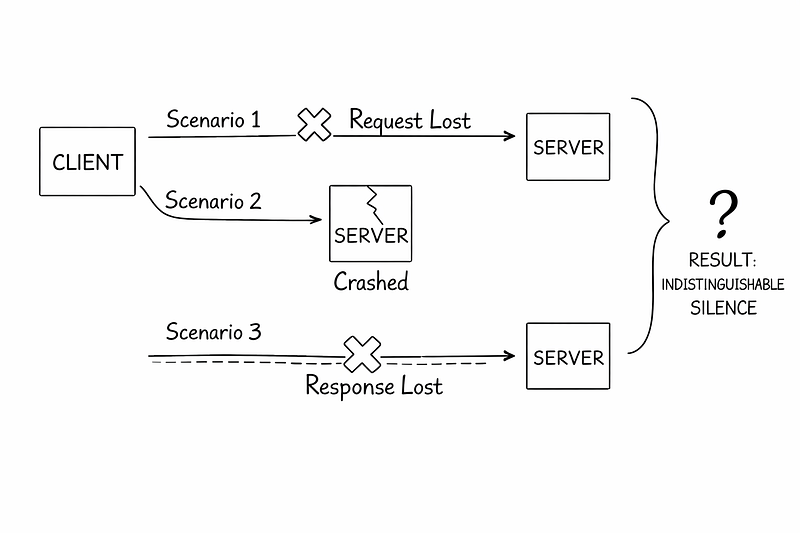
If an API request receives no response, three scenarios are indistinguishable:
The request never arrived
The server crashed while processing
The response was lost on the way back
All look identical.
In distributed systems, silence is not success. It is ambiguity.
We accept this uncertainty because packet switching maximizes network utilization and keeps infrastructure affordable. Packets compete for queue space, which introduces variable latency and unbounded delay.
Efficiency creates unpredictability.
This is not a bug in your stack. It is physics and economics.
4. Truth Is a Democracy
Because clocks drift and nodes pause, truth in distributed systems is not absolute.
It is negotiated.
A node may believe it is leader. If the quorum declares it dead, it is dead.
To prevent zombie leaders from corrupting data, systems use fencing tokens.
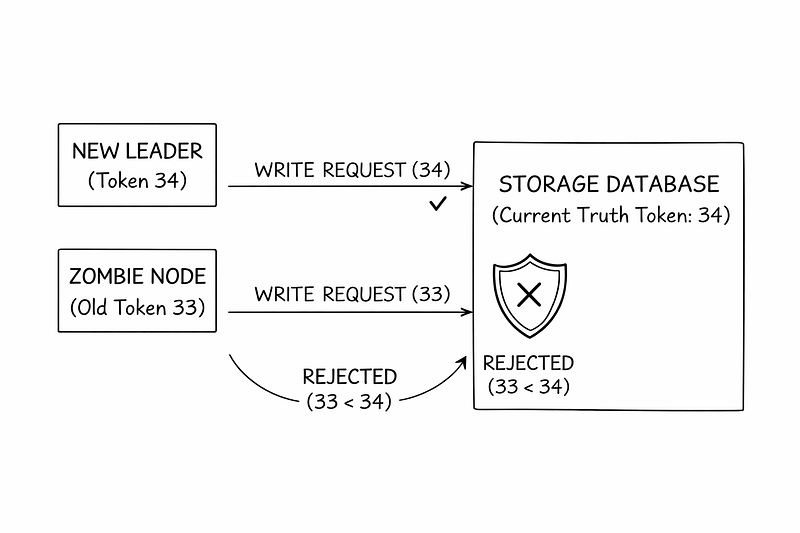
A fencing token is a strictly increasing number issued whenever a lease is granted. Storage systems must enforce it.
Example:
Node 1 receives lease token 33
Node 1 pauses
Lease expires
Node 2 becomes leader with token 34
Storage records 34 as the latest authority
Node 1 wakes and attempts a write using token 33
Storage rejects the write
The zombie is neutralized.
Leadership is enforced by monotonic truth, not belief.
5. Byzantine Reality
Most distributed systems assume nodes are unreliable but honest. They may crash, but they do not lie.
But failures are not always benign.
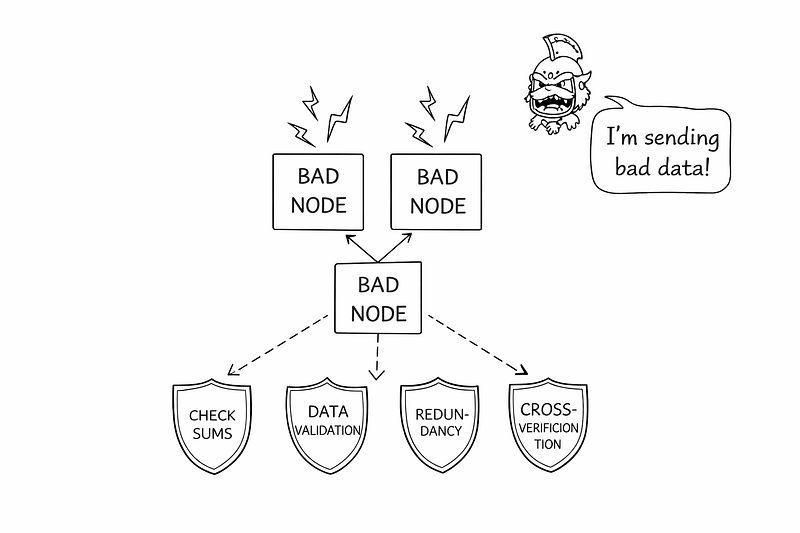
Cosmic radiation can flip bits in memory. Hardware faults can corrupt CPU registers. Disk firmware bugs can return incorrect data. Software bugs can cause nodes to behave inconsistently.
When nodes produce conflicting or incorrect outputs, you face Byzantine faults.
Consensus algorithms cannot save you if every node runs the same flawed logic.
Defense in depth is required:
Checksums
Redundant validation
Cross-node verification
Data integrity auditing
Trust must be engineered.
The Ultimate Tradeoff
Distributed systems trade simplicity for scale and fault tolerance.
You constantly balance:
Safety
Nothing bad happens.
Liveness
Something good eventually happens.
Guarantee one too strongly and you weaken the other.
The deeper you study system design, the more humility you gain. Distributed systems are not just a programming challenge. They are a lesson in uncertainty.
Before introducing consensus algorithms, quorum logic, and clock uncertainty into your architecture, ask one honest question:
Can this run on a single larger machine?
If yes, do that.
If no, welcome to the physics of distributed systems.
I am still early in my own journey and learning every day. If you have debugged brutal distributed failures in production, I would genuinely love to hear your story.
Follow for deep dives into distributed systems, reliability engineering, and real-world system design lessons.



